
この記事では、n8nでRSSを「新しいものが上にくるよう日付順に蓄積する」だけのフローを作ろうとして何週間も詰まった実体験と、最終的にたった1つの関数で解決できた話を書いています。
「毎日RSS収集をしていき、新しい日付がが上にくるように積み上げるだけ」。
たったそれだけのことで、何週間も溶かしました。爆 Obsidianに収集されるたびに、下へ下へ追加されていくので、最初はいいんですが、これが何ヶ月にもなると下までスクロールするのが大変で・・・ Obsidianにもしかして日付順にできる機能とかあるのかな?っておもったけど、見るたびにしないといけないのでn8nで直すぞ、と腰を上げました。
皆さんの中にも「n8nでファイルに蓄積したい」と思ったことがある方、いるんじゃないかな。ぜひ参考にしてみてください。
そもそもやりたかったことはシンプルだった
やりたいことを一言で言うと、
「テック系RSSを毎朝読んで、それぞれカテゴリ分けも自動でしてもらって新しい日付のまとまったニュースをObsidianのファイルの一番上(タイトル下)に追加していく」
これだけです。普通のRSSリーダーアプリがやってることと同じことを、自分のサーバー(SynologyのNAS)に立てたn8nでやりたかっただけ。
なぜかというと、ブログのネタをObsidianで管理しているので、同じ場所に情報を集めたかったんですよね。Feedlyとか使えばいい話なんですが、「ぜんぶ手元に集める」というのが個人的にこだわりでして笑
ワークフロー自体は難しくなくて、こんなイメージです。
- 毎朝スケジュールトリガーで起動
- RSSを読み込む
- テキストに整形してファイルに書く
これだけのはずだったんです。ところが「新しいものを一番上に」というたった一条件が、思ってたより複雑でした。
単純に追記(append)するだけなら古いものが上に来ちゃうんですよね。末尾に足していくわけなので。「じゃあ既存のファイルを読み込んで新しい内容と合体させて上書きすれば?」と思うじゃないですか。
そこから地獄が始まりました( ゚д゚)
詰まりポイント①:ファイルを「読んで書く」がn8nと相性最悪だった
最初に試したのは「Read Binary File」ノードで既存ファイルを読み込んで、新しい内容と結合して上書きする方法。
理屈は合ってます。でも実際にやってみると、バイナリデータで返ってくるので文字列として使うためにひと手間かかる。変換の方法もドキュメントを読んでも「で、実際どう書くの?」ってなる。
なんとかテキストとして読めるようになったと思ったら、今度は初回起動時(ファイルがまだない)にエラーで止まるという問題。
「ファイルがなければ新規作成、あれば読んで結合」という分岐を作ろうとしたら、ノード構成がどんどん複雑になっていって。。。。で結局できないので、良し潔く次へ行こう。と♪( ´θ`)ノ
詰まりポイント②:「じゃあSSHでコマンド叩けばいいやん」作戦も玉砕
「n8nのノードにこだわらなくていいじゃないか」と思って、SSHノードでサーバーに直接コマンドを打つ方法も試しました。
echo "新しい内容" > /tmp/new.txt
cat /tmp/new.txt /existing/file.txt > /tmp/merged.txt
mv /tmp/merged.txt /existing/file.txtシェルスクリプトなら普通にやることですよね。でもn8nからSSH経由でやろうとすると、パスの問題、権限の問題、改行コードの問題が次々と出てくる。
しかもSSHノードって「エラーが起きたかどうか」の判定が難しくて、失敗しても静かにスルーすることがある。「動いてるはずなのにファイルが更新されてない」という状況が何度も発生して、「んもぉ〜〜〜〜!!!」ってなりながらデバッグしてました o(`ω´ )o
詰まりポイント③:Execute Commandも似たような感じだった
「SSHじゃなくてローカルのコマンドを実行するExecute Commandノードは?」と試したんですが、これも似たような問題にぶつかりました。
地味に困ったのが「n8nのデータとシェルコマンドの間でのデータの受け渡し」でして。RSSのタイトルって「【速報】」とか「”クォート付き”」とか記号がよく入るじゃないですか。それがシェルに渡る瞬間にことごとく崩れる。
RSSの記事タイトルにはそういった地雷がおおいです笑
詰まりポイント④:Mergeノードで解決しようとした
「ファイル操作を諦めてn8nのデータフロー内で解決できないか」と方針転換して、今度はMergeノードを使う方法を試しました。
「今日のデータ」と「過去のデータ(ファイルから読んだもの)」をMergeで合体させて書き出す——という構成です。概念的には正しと思うんですよ。
でもMergeノードって「同じワークフロー実行の中の複数ストリームを合体させる」ためのもので、「今日の実行と昨日の実行のデータを合体させる」ためのものじゃないんですよね。
「なんか動いてるけど中身がおかしい」
なので、全然違うアプローチをいろいろClaude君にしらべてもらって、エフォートモードも最強にして世界中からWebFetchで情報もってきて!って書いて。 そしたら・・・
答えはn8n自身の中にあった
Claude君見つけてくれたんですよ。
$getWorkflowStaticData('global') という関数。
n8nには「ワークフローをまたいで値を保持できる変数」が存在します。
データベースもいらない、外部ファイルの読み書きもいらない。n8n自身が「このワークフロー専用の永続データ」を持っておいてくれる機能。
なんすかこれ。あるじゃないですか笑
使い方はCodeノード(JavaScriptが書けるやつ)の中でこう書くだけ:
// 保存済みデータを取得
const staticData = $getWorkflowStaticData('global');
const existing = staticData.collectedItems || [];
// 今日取得した新しいデータ
const newItems = $input.all().map(item => item.json);
// 新しいものを上に、古いものを下に結合。重複は除去
const existingUrls = new Set(existing.map(i => i.url));
const unique = newItems.filter(i => !existingUrls.has(i.url));
const merged = [...unique, ...existing];
// 30日分だけ保持(古いものは捨てる)
const cutoff = new Date();
cutoff.setDate(cutoff.getDate() - 30);
const filtered = merged.filter(i => new Date(i.pubDate) > cutoff);
// 保存
staticData.collectedItems = filtered;
return filtered.map(item => ({ json: item }));これだけ。あのSSHも、ファイル読み込みも、Mergeの格闘も、ぜんぶいらなかったんですもの。
1ヶ月くらいで更新かかればそこまで膨大にならないかなって。なので30日にしました。
最終的なワークフローは5ノードだけ
今動いているワークフローはこれだけです:
Schedule Trigger(毎朝6時)
↓
RSS Read(複数フィードを読み込む)
↓
Code in JavaScript(静的データで積み上げ処理)
↓
Convert to Text File(テキストに変換)
↓
Write File to Disk(Obsidianに保存)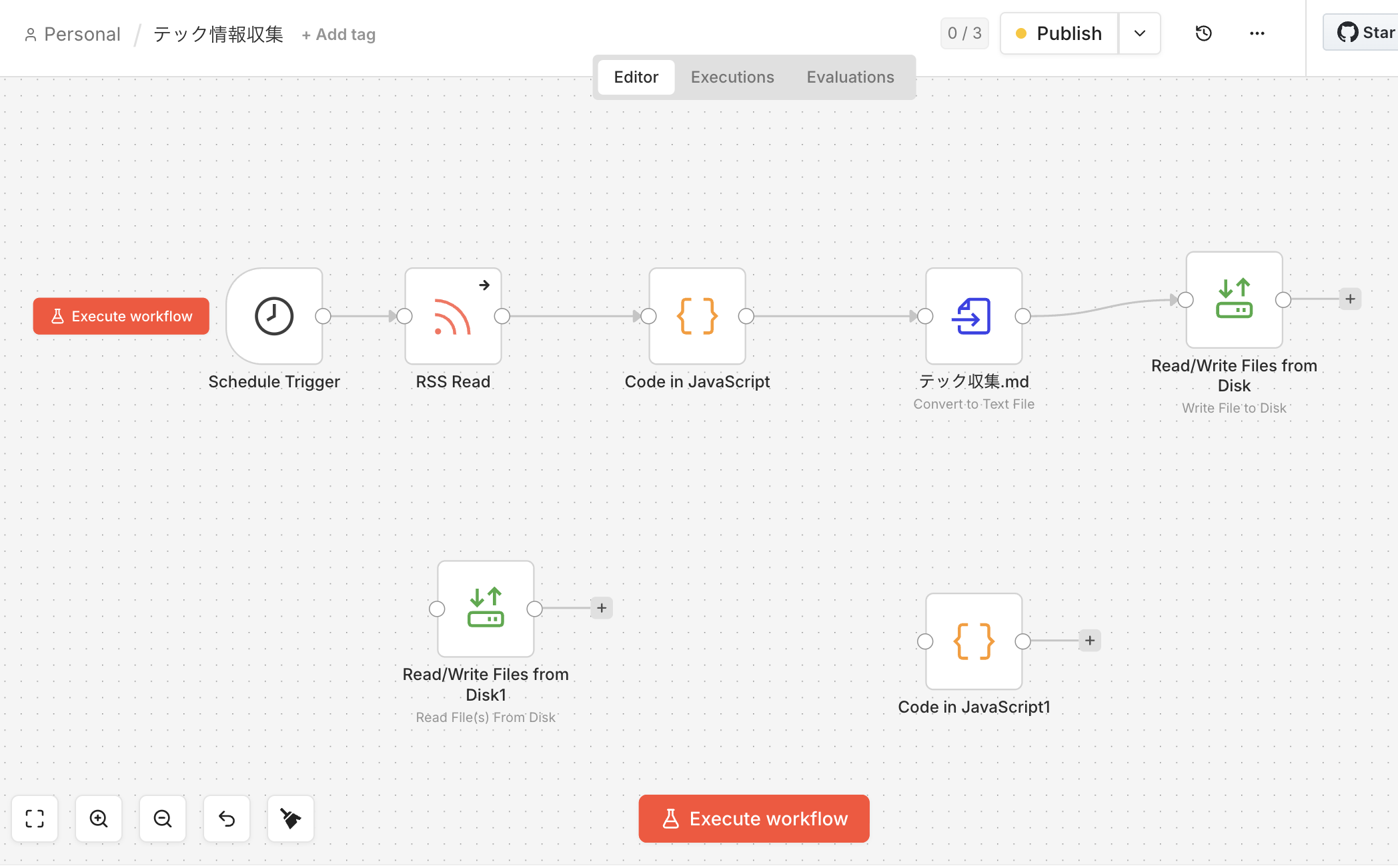
したにいろいろ試した残骸ものこってます・・・
いろいろ試行錯誤した割にはシンプルすぎます。
30日間ローリングで蓄積、重複なし、新しい順——全部ちゃんと動いています♪( ´▽`)
私のobsidianのRSSテック
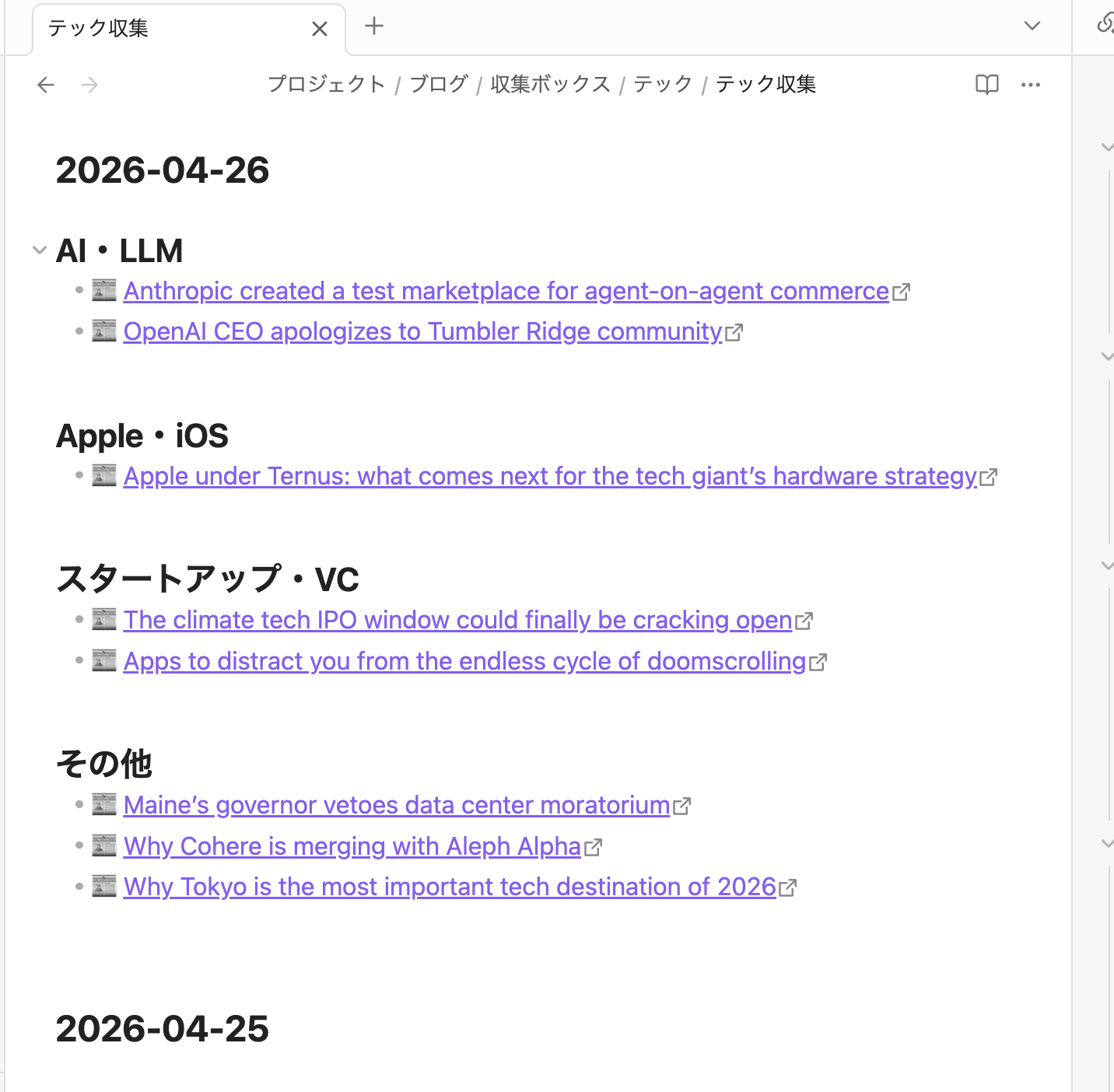
この4月25日の上に4月26日を出すのがすっごい苦労しました。
n8nで「積み上げ系」処理をやろうとしている同士へ
この件で学んだことをまとめると、こんな感じです。
- 「ファイルを読んで書く」はn8nが最も苦手なパターンのひとつ。データフロー型のツールなので、前回の実行値を今回に持ち越すのが向いていない
$getWorkflowStaticData('global')は知られていないのにすごく便利。「前の実行の値を次の実行に引き継ぎたい」ユースケースにドンピシャ- シンプルな要件ほど、シンプルな解法を信じて探し続けること。複雑なアプローチを5つ試した結果が「n8nにもともとそういう機能がある」だった
何週間もかけてたどり着いた答えが、「n8nにもともとそういう機能がある」でした。。。。
同士の皆さんが同じ罠にはまらないように、この苦戦記録をここに残しておきます。少しでも参考になれば、スーツマン冥利につきます(。•̀ᴗ-)✧












コメントを残す