
この記事でわかること:KOKOROがSynologyで動かなかった理由・Edge TTSへの切り替え手順・AnkiConnect接続の落とし穴・Obsidian_to_Ankiで解決した最終フロー・mp3に?が付くバグの真相
前回の記事でシャドーイング教材ジェネレーターの設計を書いた。「この記事ストックしたいっていう内容(URLとか文章のコピペ)を投げるだけで音声付きのAnkiカードが自動生成される仕組みを作る」というやつ。
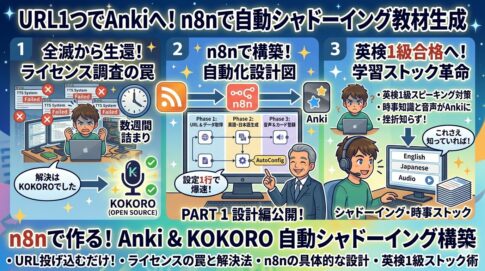
設計だけなら夢があっていいんですが、実装はそうは簡単に問屋はおろさない笑。今回はその実装に向けての記録です。
ひとことで言うと「最初の計画通りに全然ならなかった」話。TTS(音声生成)で詰まって、AnkiConnectでも壁があり、最終的に「既存の仕組みで全部解決できた」というオチになりました。詰まりポイントも全部書いたので、同じ環境(Synology + n8n + Anki)で作ろうとしている人の参考になればうれしいです。
KOKOROをSynologyに入れてみた(断念まで)
最初はKOKOROというオープンソースのTTSをSynologyで動かす予定でした。PART1で書いた通り。
Container Managerのregistryで hwdsl2/kokoro-server を検索してインストール。起動までは何の問題もなく。
詰まり①:ポートマッピングが自動割り当て
Container ManagerのPort Settingsを確認したらデフォルトの8880ではなく5桁の番号が割り当てられていた。Port Settingsで実際のポートを確認して、/docs(Swagger UI)にアクセス。n8nのHTTP Requestのポートを合わせたら接続はできました。
詰まり②:NNPACKエラーでCPUが100%に
n8nからリクエストを投げても15分以上かかってタイムアウト。コンテナのログを見ると:
NNPACK: Unsupported hardwareスーツマンの自宅NASサーバーDS220+はCeleron J4025。PyTorchのCPU高速化命令(NNPACK)に非対応で、KOKOROがCPUを使い切ってn8n自体もオフラインになるという副作用が出た。
詰まり③:ffmpegもタイムアウト
音声変換だけでも試してみたけど ffmpeg timed out after 60 seconds。DS220+ではハードウェア的に難しいのかな・・・と、時間をかけず他の方法もきっとあると判断して断念。KOKORO TTSのコンテナとイメージ(1.8GB)を削除した。
KOKOROのイメージが1.8GBあったので皆さんも試すときはディスク残量に注意です。きっとNASならそこまで容量常にパンパンにはならないとおもいますが。
代替TTS選定の話
KOKOROを諦めて他のTTSを調べた。
Gemmaローカル案は即却下。DS220+は最大6GB RAMで、Gemma 2Bすら厳しい。
Google Cloud TTSはいい選択肢だったんですけど、クレジットカード登録が必要なのが引っかかったんですよね。月400万文字無料なので実質無料なんですが、やっぱりAPIでの呼び出し?あまりよくわかりませんが、クレカを登録すると知らないうちにものすごい課金がくるみたいな記事を見かけることが多くなり、ちょっとした心理的ハードルで後回しに。きっちり勉強して設定をきちんとできればいずれ使ってみたいです^^
そこでいろいろCLAUDE君に探してもらって見つけたのが Edge TTS(travisvn/openai-edge-tts)。
完全無料・APIキー不要(任意設定)。処理はMicrosoftのサーバーで動くのでSynologyのCPUをほぼ使わない。KOKOROと同じAPIの形式(/v1/audio/speech)なのでn8nの設定変更が最小で済む。非公式なので突然止まるリスクはあるが、個人用途なら許容範囲。
個人用途だし、十分すぎる選択肢を発見しました。これで試してみましょう♪( ´θ`)ノ
Edge TTSのセットアップ
Container Managerで travisvn/openai-edge-tts をインストール。設定はシンプル:
- ポート:
5050:5050で固定 - 環境変数:
API_KEYを任意の文字列で設定(なくてもOK)
n8nのHTTP RequestのHeaderに Authorization: Bearer <APIキー> を追加して、Bodyにこれを投げる:
{
"input": "Hello, this is a test.",
"voice": "en-US-AriaNeural"
}音声ファイル(mpga形式)の取得に成功 🎉 KOKOROで詰まってた分、あっさり動いて拍子抜けした笑。 面白いのがいろいろアクセントも変えれるし、このセンテンスをかえればいろいろ人が話したように話してくれる、すごいね〜・・・・
AnkiConnect接続で半日詰まった話
音声の取得はひとまずうまくいきそうなので、お次の難関はAnkiConnectへの接続ということで。
MacのAnkiに直接カードを追加しようと、いろいろCLAUDE君と相談。試したこと全部書きます:
- AnkiConnect 設定で
webBindAddress: 0.0.0.0に変更、直接N8NのNASからMACのなかのAnkiカードへダイレクトで追加ができる他挑戦。 - Tailscaleで「Allow incoming connections」ON
- macOSファイアウォールOFF
いろいろ試してみたんですが、どれもこれもタイムアウト。tcpdumpで確認したらMacにパケットが全く届いていなさそう。ip link show でSynologyを確認したら、Tailscaleインターフェース(tailscale0)が存在しない。
根本原因:SynologyのTailscaleはユーザースペースモードで動作している。Tailscale独自プロトコル(tailscale ping)は通るが、n8nのHTTP RequestなどのTCPはルーティングされない。同じ環境でハマる人は多いんじゃないかと思う。
tailscale ping は通るのにHTTP Requestは通らない、という現象にけっこう悩まされました。半日ほどがんばってみたんだけど笑
解決策:Obsidian_to_Ankiをそのまま使う
途方に暮れて考えていたら気づいた。すでに使っている仕組みでとりあえずいっか。と。
Obsidian_to_Ankiプラグイン。これがすっごく便利ですよ、結構つかってるんですけど、これがn8n→Anki接続の問題を全部解決してくれそう。AnkiConnectへの直接TCP接続もいらずObsidian にさえはいってこればあとはAnkiにワンクリックで同期できちゃう!というプラン。
過去のAnki自動化の遍歴
Python常駐スクリプト → ターミナル占有が嫌で断念
↓
Macフォルダアクション → Google DriveフォルダではNG
↓
rsync + launchd方式 → 設定が複雑すぎた
↓
Obsidian_to_Ankiプラグイン ← 今稼働中Obsidian_to_Ankiのプラグインは ![[ファイル名.mp3]] がかいてあるカードのテキストをスキャンするとき、mp3ファイルをvault内から探してAnkiのメディアフォルダに自動コピーしてくれる。テキストとMP3が同じタイミングでAnkiに入るからすごい便利よね・・・
最終フロー(確定版)
n8n
├─ card.md → Obsidian Vault(英語/シャドーイング教材/)に書き込み
└─ audio.mp3 → 同フォルダに書き込み
↓
Synology Drive → Macに自動同期
↓
ObsidianでAnkiアイコンをクリック(手動トリガー)
↓
Obsidian_to_Ankiプラグイン
├─ MP3 → Ankiメディアフォルダにコピー
└─ カードテキスト → Ankiデッキに追加「最新技術で直接つなぐ」より「既存の動いている仕組みをつなぎ合わせる」方がうまくいくパターン、n8nをやっているとよくある気がする笑。まぁ個人の環境次第だけど。
n8nのdocker runコマンドに -v /volume1/homes/●●●/Obsidian-Vaults:/obsidian がすでに入っていのでContainer Managerの設定追加は一切不要で、n8nコンテナ内から /obsidian/My brain/ でVaultにアクセスできる状態がすでにできていたのでこれを最初からつかえてたら回り道せずにいけたなぁと。
n8nフルフロー接続
まずつくってみたn8nフローはこちら:
Form Trigger
→ Prompt Code(プロンプト構築)
→ Basic LLM Chain(Gemini 2.5 Flash)
→ Card Code(カードmd生成)
→ Convert to Text File
→ Write File(.md)
→ Edge TTS HTTP Request(音声生成)
→ Write File(.mp3)Geminiのプロンプトは「B2→C1レベルで100〜120文字に圧縮・重要表現5つ・関連語彙5〜8語・日本語訳・カテゴリとタイトル、全部JSON形式で返して」という内容にした。
しかし途中でいくつかエラーが出ました:
$('Form Trigger')のノード参照エラー → URL・Titleフィールドは空文字で代替- expressionsが
undefined: undefined→ プロンプトのフィールド名とコード変数名のズレ(e.en / e.jpに修正) - Write FileがBinaryデータ要求 → Convert to Text Fileノードを挟んで解決
- パスに
/My brainが抜けていた
Claudeに調べてもらいながら一個ずつ潰していった感じです笑。
最後の2大バグ
① Translationフィールドが正しく入らない
カードは届いているのに英文の日本語訳のAnkiカードフィールドTranslationが空。英文と日本語訳が同じTextフィールドに入っていた。
原因を掘っていくと、Obsidian_to_Ankiの fields_dict(フィールド名キャッシュ)が根本原因だった。Ankiに Translation フィールドを追加した後でプラグインの「Regenerate Note Type Table」を押してもキャッシュが更新されない。
何度やってもダメで、Vault内のプラグイン設定ファイルを直接確認することにした。.obsidian/plugins/obsidian-to-anki-plugin/data.json を開いたらTranslationが入っていないことを確認。Obsidianを終了させた状態でdata.jsonを直接編集してTranslationを追記、起動し直したら解決した。
Regenerateが効かないときはdata.jsonを直接見ろ、というのが今回の教訓。次も同じ問題にあったらきっと忘れてるだろうけど笑
② 音声ファイルがAnkiのmediaフォルダに届かない
カードは届くんですよ。Ankiでバッチリカードは同期されるんですが、mp3の音声の同期がされないんですよね。でもmp3はObsidianにきちんと生成されてます。collection.media を直接確認するとmp3のファイルがない。なるほど、Obsidianの音声リンクの記法を間違えていたんでしょうね。
// ❌ これだとObsidian_to_Ankiがファイルを見つけられない
Audio: [sound:shadowing_xxx.mp3]
// ✅ Obsidian埋め込み記法にすると正しく動く
Audio: ![[shadowing_xxx.mp3]]なぜ ![[…]] が必要なのか。Obsidian_to_Ankiは getFirstLinkpathDest() という内部関数でvault内を検索する。![[…]] 記法を使うとこの関数が正しく動くそうです。[sound:…] 直書きでは検索がスキップされる。GitHubのIssue #217にも同様の報告がありました。
ファイル名を読めるように改善しようとした
フローが動いた後、細かい改善をした。最初のファイル名が shadowing_1778298797953.md というタイムスタンプ形式で、何の記事かわからない状態だった。GeminiにcategoryとshortTitleも生成させて、ファイル名に組み込むようにした:
変更前: shadowing_1778298565403.md
変更後: 20260509【政治・外交】AI声優権保護の新ガイドライン.mdPCで見るといい感じ。カテゴリはGeminiが「医療・健康、環境・気候、政治・外交、経済・ビジネス、テクノロジー、社会・文化、教育、スポーツ、科学」から判断するようにノードに追加。「あ、これあの記事のやつだ」とすぐわかるし、まさに英検に特化したシャドーイング生成アプリらしい管理ができるようになってきた。
でもスマホ(iPhone)で音声が聴こえなかった。
PCのAnkiでは再生できているのに、スマホのAnkiだと音声だけ届かない。原因を調べたら、AnkiWebのスマホ同期サービス(AnkiWeb)が漢字・ひらがなを含むファイル名のアップロードに対応していないことがわかった。
せっかく読みやすくなったのに、スマホで使えなければ意味がない。泣く泣く英数字のファイル名に戻しました。
mp3に?が付くバグの真相
音声をサブフォルダ(audio/)に分離しようとしたら、mp3ファイル名に ? が混入するバグが発生しました。っもぉ〜〜〜〜勘弁してください・・・でも乗り越えられる困難は楽しい🎵
静的パスでも、式でも、Codeノードでbinaryを作り直しても、どうやっても消えない。これがほんとにつまりました。
prepareBinaryDataでbinaryを完全に作り直す → まだ?- 完全固定パス
test.mp3→test.mp3?????(5個に増えた) - ディレクトリパス指定 → EISDIRエラー
犯人はn8nのバグではなく、自分が途中で追加したCodeノードだったみたいです。
てへっ(๑╹ω╹๑ )
HTTP RequestとWrite File to Diskの間に「binaryを作り直すCodeノード」
を挟んでいたせいで ? が発生していた。
HTTP Request → [Codeノード削除] → Write File to Disk(直結)これだけで ? が消えました。サブフォルダへの書き込みも、英数字のファイル名も問題なく動き、無事mp3が再生され、キチンとテキストにリンクがつきました!!
英語/シャドーイング教材/
├─ 20260509_culture_rv0l.md
└─ audio/
└─ 20260509_culture_rv0l.mp3「自分が追加したものを疑う」はデバッグの鉄則だと改めて実感した笑。
まとめ:詰まりポイント一覧
| 詰まり | 原因 | 解決 |
|---|---|---|
| KOKOROがタイムアウト | DS220+でNNPACK非対応(CPU限界) | Edge TTSに変更 |
| AnkiConnect接続不可 | SynologyのTailscaleがユーザースペースモード | Obsidian_to_Ankiで回避 |
| Translationが入らない | fields_dictキャッシュが古い | data.jsonを直接編集 |
| 音声がAnkiに届かない | [sound:…]ではなく![[…]]が必要 | Obsidian埋め込み記法に変更 |
| mp3に?が付く | HTTP RequestとWrite Fileの間にCodeノードを挟んでいた | Codeノードを削除・直結に戻した |
「最初の設計通りにはいかない」の連続だったけど、そのぶん解決策を考える面白さがあった。特に「Obsidian_to_Ankiがすでにあったじゃないか」という気づきのタイミングはちょっと嬉しかった笑。
次のPART3ではようやくできたシャドーイング兼リーディングの自動カード作成の紹介と実際に1週間使ってみての改善・感想を書きます。

今日学んだの英語表現(B2〜C1)
一応英検1級目指してるスーツマンのこの記事のトピックから使えるフレーズをAIがピックアップ。n8n・Anki・TTS系の英語記事を読むときに頻出する表現です。
① user space(= ユーザースペース)
Tailscale on Synology runs in user space, which means standard TCP traffic won’t route through the interface.
OSのカーネルではなくアプリケーション側で処理が動いていること。「kernel space」と対比で使われる。ネットワーク・セキュリティ系の技術記事で頻出。
② fallback(= 代替手段・フォールバック)
When the primary method failed, we needed a reliable fallback to keep the pipeline running.
本来の方法が使えないときの代替案・保険の仕組み。「fallback option」「fall back to X」の形でよく出てくる。今回のEdge TTSがまさにこのポジション。
③ parse(= 解析する・パースする)
The plugin parses the card format and extracts each field name from the cached configuration.
テキスト・データを読み取って処理できる形に変換すること。「parser」「parsing error」など派生形も多い。n8n・プログラミング・APIの記事ではほぼ毎回登場する。

















コメントを残す